Machine Learning und reale Versorgungsdaten: Neue Übersicht zu heterogenen Behandlungseffekten
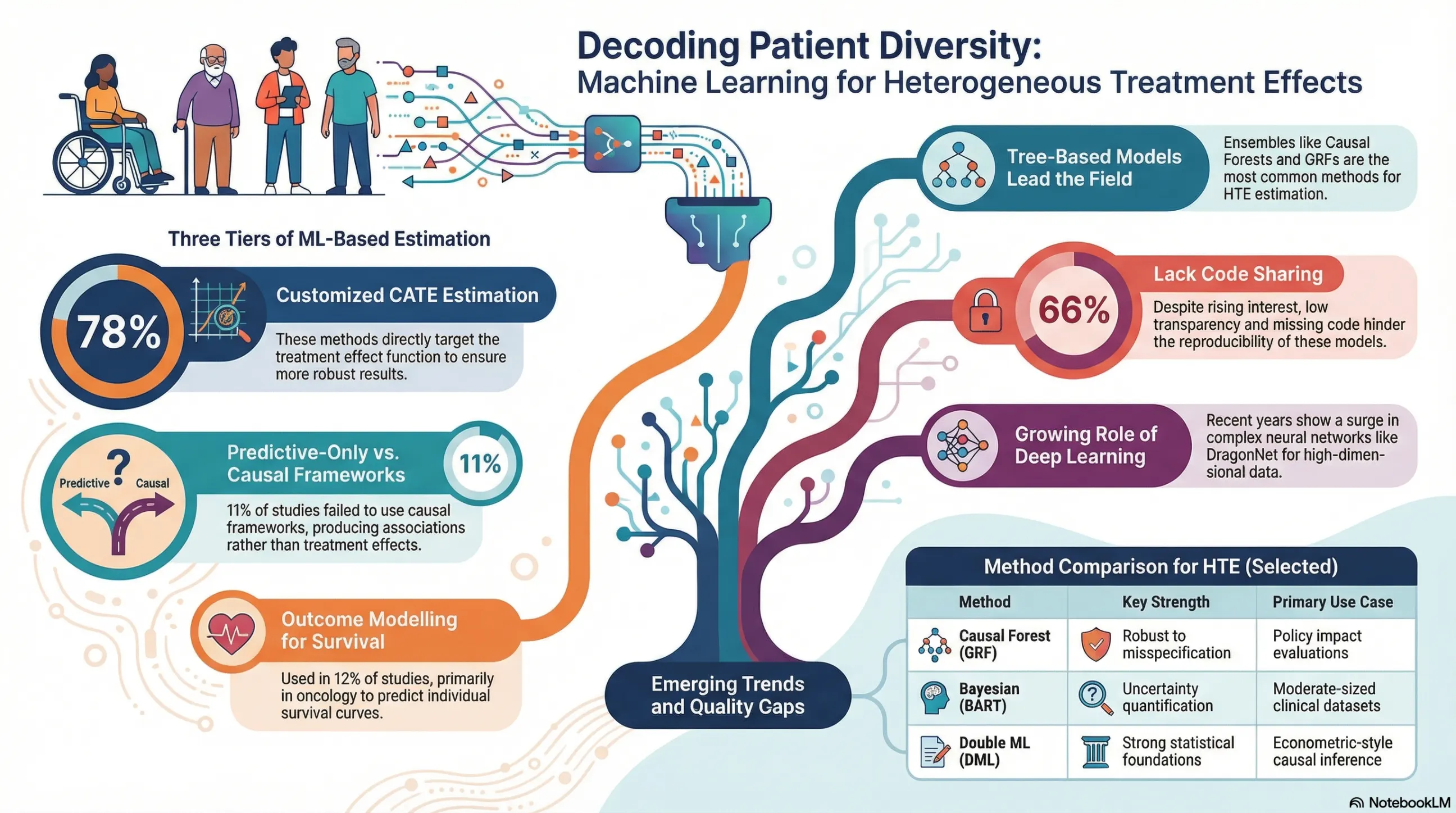
Wie unterschiedlich Patient:innen auf dieselbe Behandlung reagieren, ist eine zentrale Frage für eine zielgerichtete und effiziente Gesundheitsversorgung. In einem aktuellen Übersichtsartikel analysieren Forschende der Universität Hamburg und der Universität Siegen systematisch, wie Machine-Learning-Methoden genutzt werden, um heterogene Behandlungseffekte (Heterogeneous Treatment Effects, HTEs) auf Basis von Real-World-Daten zu schätzen.
Die Studie, die in der Fachzeitschrift Value in Health erscheint, wertet 74 internationale Arbeiten aus, die zwischen 2014 und 2025 veröffentlicht wurden. Die Autor:innen kategorisieren die eingesetzten Methoden in drei Gruppen:
(1) rein prädiktive Ansätze ohne kausale Identifikation,
(2) kausale Outcome-Modelle sowie
(3) spezialisierte Verfahren zur direkten Schätzung bedingter Behandlungseffekte (Conditional Average Treatment Effects, CATE).
Die Ergebnisse zeigen, dass tree-based Verfahren und spezialisierte CATE-Methoden zunehmend eingesetzt werden, während ihre Anwendung in der gesundheitsökonomischen Forschung bislang noch begrenzt ist. Zugleich weist die Analyse auf erhebliche Unterschiede in der methodischen Qualität und Transparenz der Studien hin. Insbesondere bei Berichtsstandards, Validierung und Reproduzierbarkeit besteht weiterer Verbesserungsbedarf.
Der Beitrag liefert damit eine strukturierte Orientierung für Forschende, die Machine Learning zur Analyse heterogener Behandlungseffekte in realen Versorgungsdaten einsetzen möchten, und leistet einen wichtigen Beitrag zur Weiterentwicklung evidenzbasierter, individualisierter Versorgungs- und Policy-Analysen.